O Falso Milagre
Todo mundo já viu aquele teste da feature que ia mudar tudo e gerar uma receita de um bilhão. O teste roda por dois meses. A equipe está ansiosa. Na hora de apresentar os resultados, a grande surpresa: o p-valor ficou em 0,06 — logo acima do limiar tradicional de 0,05.
O clima fica pesado. Muitos recursos, tempo e esperanças investidos naquela ideia genial parecem perdidos. Eis que, então, alguém levanta a mão e traz a solução, a luz no fim do túnel, o salvamento do bilhão.
"E se a gente deixar o teste rodando por mais uma ou duas semanas? Só para ver se ele 'bate' de vez?"
Um silêncio absoluto precede os aplausos lentos. Todos param para apreciar a ideia mais genial que apareceu naquela empresa. Duas semanas depois, o "milagre" acontece: o p-valor cai para 0,048. A feature é aprovada, o herói promovido. Agora é só esperar os bilhões entrarem.
Tudo parece perfeito. Mas o que pode ter ocorrido é a materialização de um falso positivo. Como isso é possível? Para explicar resultados "contra-intuitivos" da estatística, é sempre bom recorrer a um clássico: o Problema de Monty Hall.
O Problema de Monty Hall e a Ilusão da Escolha
Você pode não saber de cor o que é o Problema de Monty Hall, mas certamente já viu aquela cena do filme quebrando a banca, ou ouviu um amigo entusiasta de matemática tentando explicá-lo (as vezes é estranho perceber o quão real isso é e que ja aconteceu na sua vida).
O problema clássico consiste em um apresentador de TV, um jogador, três portas, dois bodes e um carro. O jogador escolhe uma porta. O apresentador, que sabe o que há atrás de cada porta, abre uma das portas não escolhidas, revelando sempre um bode. Ele então vira ao jogador e oferece: "Você quer trocar para a outra porta que ficou fechada?"
Intuitivamente, parece não fazer diferença. Restam duas portas, então a chance de o prêmio estar em cada uma seria de 50%, certo? Errado. Essa percepção ignora o fato crucial: o apresentador não abre uma porta aleatoriamente; ele abre uma porta com a informação privilegiada de onde está o prêmio.
A Matemática Por Trás da Porta Aberta
Ao analisar apenas a segunda decisão (trocar ou não), desconsideramos a primeira. Decompondo:
- Escolha inicial: Você tem 1/3 de chance de acertar o carro e 2/3 de chance de ter escolhido um bode.
- Ação do apresentador: Ele sempre abre uma porta com bode entre as duas que você não escolheu. Se você inicialmente escolheu um bode (probabilidade de 2/3), ele é forçado a abrir a única outra porta com bode, deixando o carro inevitavelmente na porta restante.
- Decisão final: Portanto, se você trocar, você inverte as probabilidades iniciais. Trocar te dá 2/3 de chance de ganhar; ficar, apenas 1/3.
Vamos colocar as probabilidades no papel usando o Teorema de Bayes. A beleza está em como uma única informação transforma completamente o cenário probabilístico.
Definindo os eventos:
- C₁, C₂, C₃: Carro está na porta 1, 2 ou 3 (probabilidade inicial de cada: 1/3)
- E: Evidência observada - apresentador abre a porta 3 com um bode
- Você escolheu inicialmente a porta 1
Queremos calcular:
- $P(C_1|E)$: Probabilidade do carro estar na porta 1, dado que vimos a porta 3 aberta
- $P(C_2|E)$: Probabilidade do carro estar na porta 2, dado que vimos a porta 3 aberta
Aplicando o Teorema de Bayes:
$$P(C_i|E) = \frac{P(E|C_i) \cdot P(C_i)}{P(E)}$$Cálculo das probabilidades condicionais $P(E|C_i)$:
-
Se o carro está na porta 1 (sua escolha inicial):
- O apresentador pode abrir a porta 2 ou 3 (ambas têm bodes)
- $P(E|C_1) = 1/2$ (50% de chance de abrir justamente a porta 3)
-
Se o carro está na porta 2:
- O apresentador é obrigado a abrir a porta 3 (não pode abrir a porta 2 com carro, nem sua porta 1)
- $P(E|C_2) = 1$ (100% de certeza)
-
Se o carro está na porta 3:
- O apresentador nunca abriria a porta com o carro
- $P(E|C_3) = 0$ (impossível)
Probabilidade total da evidência P(E):
$$P(E) = P(E|C_1)P(C_1) + P(E|C_2)P(C_2) + P(E|C_3)P(C_3)$$ $$P(E) = \left(\frac{1}{2}\right) \cdot \frac{1}{3} + \left(1 \cdot \frac{1}{3}\right) + \left(0 \cdot \frac{1}{3}\right) = \frac{1}{6} + \frac{1}{3} + 0 = \frac{1}{2}$$Resultados finais - a atualização bayesiana:
$$P(C_1|E) = \frac{\frac{1}{2} \cdot \frac{1}{3}}{\frac{1}{2}} = \frac{1}{3} \quad (33{,}3\%)$$ $$P(C_2|E) = \frac{1 \cdot \frac{1}{3}}{\frac{1}{2}} = \frac{2}{3} \quad (66{,}7\%)$$O que isso significa na prática:
Sua porta inicial mantém a probabilidade original de 33,3%. A porta restante dobra sua probabilidade para 66,7%. A ação do apresentador não é neutra, ela transfere probabilidade da porta que ele abre (que vai para zero) para a única outra porta que ele não podia abrir.
Simulações computacionais confirmam esses resultados matemáticos, mostrando consistentemente que trocar resulta em aproximadamente 66,7% de vitórias, enquanto manter a escolha inicial resulta em apenas 33,3%.
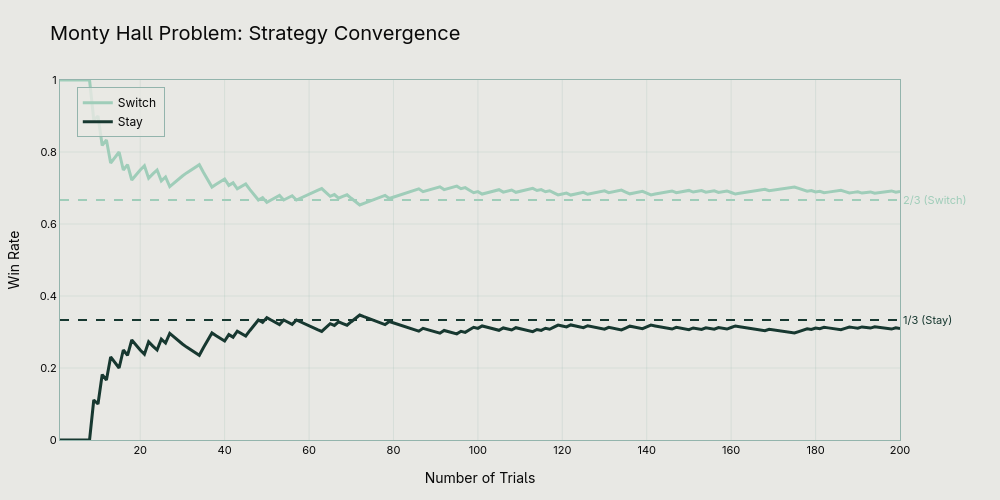
Do Cassino ao Laboratório
Agora que compreendemos como a estatística pode desafiar nossa intuição, voltemos ao nosso herói. Após essa epifania, ele percebe que seu ato de "deixar rodar mais um pouco" criou uma situação análoga ao Problema de Monty Hall.
Na analogia:
- O apresentador (com informação privilegiada) é nosso herói que decide parar ou continuar o teste.
- O jogador é o próprio teste A/B.
- O prêmio é a rejeição correta da hipótese nula (descobrir um efeito real).
- Abrir uma porta equivale a "espiar" os resultados antes do fim planejado e tomar uma nova decisão (parar ou continuar).
Ao fazer isso, ele não estava apenas dando "mais uma chance" ao teste. Ele estava alterando as regras do jogo estatístico que havia sido planejado.
Os Dois Tipos de Erro e o "Peeking Problem"
Todo teste A/B é desenhado com parâmetros pré-definidos:
- Erro Tipo I (α - Falso Positivo): A probabilidade de declarar um efeito quando não há nenhum (geralmente fixado em 5%).
- Erro Tipo II (β - Falso Negativo): A probabilidade de não detectar um efeito que existe.
- Poder do Teste (1-β): A capacidade de detectar um efeito se ele existir (geralmente 80% ou 90%).
- Tamanho da Amostra (n): Calculado com base nos parâmetros acima e no efeito mínimo detectável (MDE).
Quando você "espia" os resultados intermediários e decide estender o teste com base no que viu, você está efetivamente realizando múltiplos testes sequenciais na mesma hipótese. Isso infla dramaticamente a taxa de Erro Tipo I. É o chamado "Peeking Problem".
A matemática é implacável. Cada "olhadinha" extra aumenta suas chances de encontrar um falso positivo:
| Número de "Olhadas" no Teste | Chance Real de um Falso Positivo (α Real) |
|---|---|
| 1 (apenas no final planejado) | 5% |
| 2 | ~8% |
| 5 | ~14% |
| 10 | ~19% |
| 20 | ~25% |
| Monitoramento Contínuo | Pode exceder 30%+ |
No caso do nosso herói, ao olhar na semana 8 e decidir continuar, ele elevou seu α real para aproximadamente 8%. O p-valor de 4,8% que ele encontrado na semana 10, portanto, não era mais estatisticamente significativo no novo contexto. O "milagre" era, na verdade, uma miragem estatística.
Validação Conceitual: A analogia com Monty Hall é útil para ilustrar como informações adicionais (a porta aberta / a decisão de continuar) alteram a interpretação de uma probabilidade. No entanto, o mecanismo estatístico é diferente. No "Peeking Problem", o aumento do Erro Tipo I vem do aumento do número de comparações (testes) realizadas, um fenômeno bem descrito pela correção para comparações múltiplas. O princípio subjacente, porém, é o mesmo: violar os pressupostos do desenho experimental (neste caso, a regra de parada fixa) invalida as conclusões.
Simulações demonstram como esse mecanismo funciona: em testes A/A (sem diferença real entre grupos), cerca de 25-30% cruzam significância em algum momento quando observados continuamente, apesar de apenas 5% serem significativos no final planejado.
Código da Simulação
class ABTestSimulator:
@staticmethod
def run_aa_test(total_n: int = 10000, checks: int = 20, alpha: float = 0.05) -> Tuple[bool, bool, List[float]]:
group_a = np.random.normal(0, 1, total_n)
group_b = np.random.normal(0, 1, total_n)
p_values = []
peek_significant = False
for i in range(1, checks + 1):
current_n = int(total_n * i / checks)
_, p = stats.ttest_ind(group_a[:current_n], group_b[:current_n])
p_values.append(p)
if p < alpha:
peek_significant = True
final_significant = p_values[-1] < alpha
return peek_significant, final_significant, p_values
sim = ABTestSimulator()
n_sims = 10000
crossed, final = 0, 0
for _ in range(n_sims):
is_peek, is_final, _ = sim.run_aa_test()
if is_peek: crossed += 1
if is_final: final += 1
print(f"Alpha-crossing rate (Peeking): {crossed/n_sims:.1%}")
print(f"Final significance rate: {final/n_sims:.1%}")A Maldição do Vencedor: Quando Até Efeitos Reais Enganam
O peeking problem não apenas infla falsos positivos, ele também infla sistematicamente o tamanho do efeito observado dos resultados que cruzam o limiar de significância. Esse fenômeno, conhecido como "maldição do vencedor" (winner's curse), é possivelmente mais danoso na prática do que a inflação do Erro Tipo I.
Quando você para um teste antecipadamente (ou o estende até atingir significância), o efeito observado naquele ponto de parada não é uma amostra aleatória do efeito verdadeiro, ele é condicionalmente selecionado por ser grande o suficiente para cruzar o limiar de significância naquele momento específico. O ruído que por acaso empurrou a estimativa para cima é justamente o que disparou a decisão de parar.
Isso não é apenas uma preocupação teórica. O time de engenharia do Etsy publicou uma análise detalhada de como a maldição do vencedor afeta seu programa de testes A/B, mostrando que confiar ingenuamente nos lifts observados de experimentos vencedores leva a uma superestimação substancial do impacto real no negócio. Sua estratégia de mitigação usa estimadores de encolhimento bayesianos (Bayesian shrinkage) para descontar os lifts reportados em direção a um prior, produzindo estimativas de tamanho de efeito mais realistas.
A maldição do vencedor é pior quando o poder estatístico é baixo, exatamente as condições que surgem quando testes são subpotentes ou interrompidos antecipadamente. Estudos com poder entre ~8% e ~31% tendem a ver suas estimativas iniciais de tamanho de efeito infladas entre 25% e 50%. Em testes A/B, onde efeitos mínimos detectáveis são frequentemente otimisticamente pequenos e tamanhos de amostra são escolhidos sob restrições orçamentárias, essa faixa não é incomum.
Mesmo quando um teste estendido encontra um efeito real a magnitude observada no ponto de parada deve ser tratada com ceticismo. O efeito verdadeiro é quase certamente menor.
Como Fugir da Roleta Russa Estatística
Agora, dotado de conhecimento, nosso herói (agora um verdadeiro cientista de experimentos) busca as soluções corretas. Existem caminhos bem estabelecidos:
A Abordagem Frequentista "Clássica" (O Padrão-Ouro Simples)
- Calcule o tamanho da amostra (n) ANTES de iniciar o teste, com base no α, poder (1-β) e MDE desejados.
- Defina uma única regra de parada: execute o teste até alcançar exatamente n.
- Não olhe os resultados durante a execução.
- Tome UMA decisão no final, baseada no p-valor calculado uma única vez.
Se Você Realmente Precisa Olhar (Métodos Sequenciais)
Para quem precisa de mais agilidade, existem métodos formais:
- Correção de Bonferroni: Divida α pelo número de olhadas planejadas (ex.: 5 olhadas → use α=0.01 em cada). Problema: Muito conservador, reduz drasticamente o poder do teste.
- Procedimentos Sequenciais (O'Brien-Fleming, Pocock): Ajustam os limiares de significância (mais rigorosos no início, mais próximos de α no final) para controlar o erro global. São a solução estatisticamente válida para testes com análises intermediárias planejadas.
- P-Valores Sempre Válidos (ex.: mSPRT): Métodos avançados, como o Sequential Probability Ratio Test modificado, que calculam uma medida de evidência que permanece válida não importa quando você olha.
- Abordagem Bayesiana: Atualiza as probabilidades a posteriori continuamente com base nos dados. Permite regras de parada bem definidas (ex.: parar quando P(efeito > X) > 95%), mas exige a definição cuidadosa de um prior.
Correção para Múltiplas Comparações
O problema se agrava com múltiplas métricas ou variantes. Para 20 métricas testadas com α=5%, a chance de pelo menos um falso positivo salta para ~64%!
- Método de Benjamini-Hochberg: Controla a Taxa de Descobertas Falsas (FDR), uma abordagem menos conservadora que Bonferroni.
Da Aposta à Ciência
Estender um teste A/B "só mais um pouco" com base em resultados intermediários não é um ato de perseverança. É o equivalente estatístico a dobrar a aposta em uma mão perdida no cassino, acreditando que a próxima carta vai mudar sua sorte. As probabilidades estão estruturalmente contra você.
A experimentação rigorosa é o que separa decisões baseadas em dados de apostas disfarçadas de análise. Domine os fundamentos, planeje seu teste com antecedência e escolha o método de análise sequencial adequado se a agilidade for crítica.
Assim, você deixará de ser um jogador no cassino da aleatoriedade para se tornar um verdadeiro cientista.
Referências
- How Not To Run an A/B Test. evanmiller.org.
- Teste A/B e o Problema do Peeking - Caderno de Código. Caderno interativo do Google Colab com todos os exemplos de código usados neste artigo.
- 21 (Cena do Filme) - O Problema de Monty Hall Explicado. Famosa cena do filme "21" (2008) demonstrando o Problema de Monty Hall.
- Behind Monty Hall's Doors: Puzzle, Debate and Answer. The New York Times, 1991.
- The Monty Hall Problem: A Study. MIT Research Science Institute.
- Peeking at A/B Tests: Why it matters, and what to do about it. Johari, R., Pekelis, L., & Walsh, D. J. (2017). Proceedings of the 23rd ACM SIGKDD.
- Bringing Sequential Testing to Experiments with Longitudinal Data (Part 1): The Peeking Problem 2.0. Spotify Engineering Blog, 2023.
- Etsy Engineering. Mitigating the Winner's Curse in Online Experiments. 2025.
- Button, K. S., et al. (2013). Power failure: why small sample size undermines the reliability of neuroscience. Nature Reviews Neuroscience.
- Benjamini, Y., & Hochberg, Y. (1995). Controlling the false discovery rate: a practical and powerful approach to multiple testing. Journal of the Royal Statistical Society.
- O'Brien, P. C., & Fleming, T. R. (1979). A multiple testing procedure for clinical trials. Biometrics, 549-556.
- Wald, A. (1945). Sequential tests of statistical hypotheses. The Annals of Mathematical Statistics, 16(2), 117-186.