Quem conhece o Teorema do Limite Central (TLC, ou CLT do inglês, sigla que usaremos daqui em diante) sabe que ele é o canivete suíço da estatística. E mesmo quem nunca viu o teorema, mas trabalha com dados no dia a dia, já recorreu ao seu poder na forma daquele "vamos normalizar os dados". O que antes parecia uma distribuição indomável de repente fica familiar, tratável, mais simples de observar, ainda que essa familiaridade, vez ou outra, leve a conclusões erradas. Em estatística, muitas vezes parece que todos os caminhos levam à Normal.
Boa parte dessa intuição vem do alcance do TLC. Pesquisas eleitorais, testes A/B, controle de qualidade, aferição de erros em experimentos: a lista de problemas que ele resolve atravessa quase todas as áreas mais pesquisadas da estatística. Daí a imagem do canivete suíço. Mas é justamente por sustentar tanta coisa que sua enunciação, e principalmente sua prova, é bem mais complexa do que a fama sugere. Na minha experiência em um curso de graduação em estatística, uma demonstração "simples" do teorema (simples no sentido de assumir hipóteses mais fortes do que as versões robustas exigem) ainda consumia uma sequência exaustiva de três a quatro aulas só para que a intuição da prova assentasse.
Para ter uma ideia do que significa "afrouxar" essas hipóteses, vale comparar a versão de graduação com a de Lindeberg–Feller:
| Hipótese | Prova de graduação | Lindeberg–Feller CLT |
|---|---|---|
| Distribuição das variáveis | i.i.d. (idênticas) | Apenas independentes (podem ser diferentes) |
| Média | E[X_i] = 0 |
Média própria de cada termo (centralizada) |
| Variância | E[X_i²] = 1 (finita e igual para todas) |
Finita, podendo variar termo a termo (s_n² = Σ Var(X_i)) |
| Momentos de ordem superior | Exige E[X_i⁴] < ∞ |
Não exige nenhum momento acima do segundo (a variância finita basta) |
| Condição extra | Nenhuma além do quarto momento | Condição de Lindeberg: nenhum termo domina assintoticamente s_n² |
| Generalidade | Caso particular, mais restrito | Necessária e suficiente, mais geral |
E dá para afrouxar ainda mais. É possível quebrar até a exigência de independência: a abordagem via martingales mostra que, se a correlação da variável atual com o passado não for previsível, o TLC continua valendo. Mas não vamos nos adiantar.
O teorema, sem rodeios
Versão formal
Seja $X_1, X_2, \dots, X_n$ uma sequência de variáveis aleatórias independentes e identicamente distribuídas (i.i.d.), com média $\mu = E[X_i]$ e variância finita $\sigma^2 = \text{Var}(X_i) < \infty$. Defina a média amostral $\bar{X}_n = \frac{1}{n}\sum_{i=1}^n X_i$. Então, quando $n \to \infty$, a variável padronizada
$$Z_n = \frac{\bar{X}_n - \mu}{\sigma/\sqrt{n}}$$converge em distribuição para uma normal padrão, isto é, $Z_n \xrightarrow{d} N(0,1)$. Equivalentemente, $\sqrt{n}(\bar{X}_n - \mu) \xrightarrow{d} N(0, \sigma^2)$.
Versão não tão formal
Se você tirar amostras grandes o suficiente de praticamente qualquer população (não importa o formato da distribuição original, pode ser assimétrica, bimodal, o que for), a média dessas amostras vai se comportar como se viesse de uma distribuição normal, centrada na média real da população, com desvio padrão igual a $\sigma/\sqrt{n}$ ("erro padrão").
Na maioria dos casos, $n \geq 30$ já é considerado suficiente, embora distribuições muito assimétricas ou com caudas pesadas possam exigir amostras maiores.
E a "função da normal" (a PDF) é:
$$f(x) = \frac{1}{\sigma\sqrt{2\pi}}\, e^{-\frac{1}{2}\left(\frac{x-\mu}{\sigma}\right)^2}$$De onde, afinal, sai essa convergência?
Aqui mora o estranhamento. Por que não importa o quão bizarra seja a distribuição original (uniforme, constante, exponencial), se continuarmos tirando amostras dela, a média amostral converge para uma Normal?
Breve aviso: o que vem a seguir ajuda a entender por que a forma que emerge é justamente a Normal, e não por que existe convergência. A convergência em si só fecha mais adiante, quando juntarmos essa forma à ideia de que a Normal é estável sob somas.
Existem várias metáforas para domar essa intuição. Vou reproduzir a minha favorita aqui e deixar nas referências algumas manipulações que talvez funcionem melhor para você.
A ideia é tratar o processo de amostragem como um lançamento de dardos. O lançador é o experimento; sua habilidade/precisão é a distribuição de onde se tiram as amostras; o alvo é o resultado; cada lançamento é uma amostragem; e a posição final dos dardos no alvo é a distribuição das amostras.
Para deixar a "mágica" mais evidente, vamos escolher de propósito a pior origem possível: a habilidade do nosso lançador segue uma Exponencial(1) (Figura 1), uma curva que não tem nada de sino. Ela só assume valores positivos, dispara perto de zero e decai rápido, sem nenhuma simetria. É o exemplo mais "anti-Normal" que se poderia pedir, e é justamente a partir dele que a Normal vai emergir.
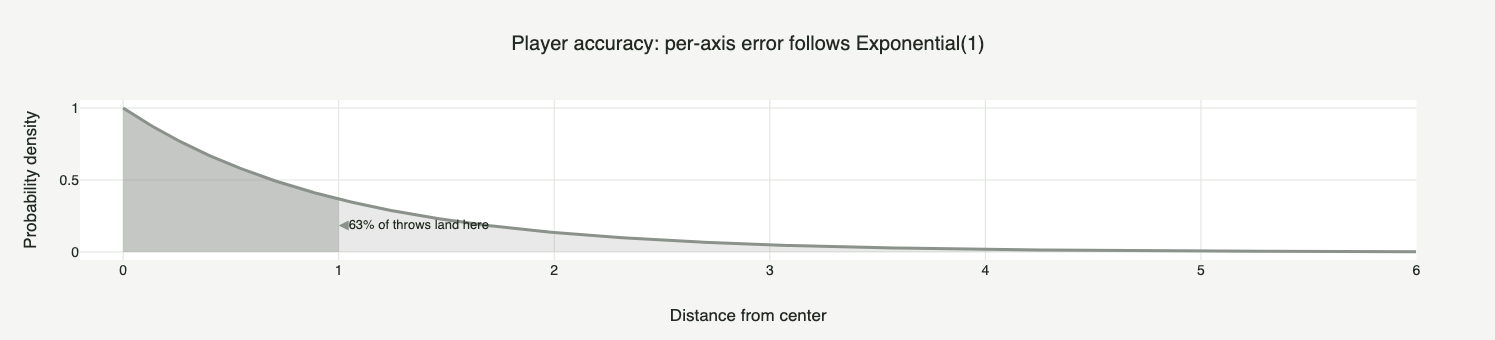
Nesse enquadramento, a média da distribuição original é o centro do alvo, e o desvio padrão (a escala) é o raio em torno do qual o lançador "erra" cada arremesso. Repare que isso vale para qualquer distribuição de origem: você sempre pode afirmar que a média representa o centro e a escala, o tamanho do erro ao redor dele.
Agora decomponha cada lançamento em dois eixos, $x$ e $y$. Em cada eixo, o tamanho do erro segue a distribuição de origem (a Exponencial da Figura 1), e o sentido (para a esquerda ou para a direita, para cima ou para baixo) é decidido no cara ou coroa. Juntando módulo e sentido, o erro por eixo vira uma curva simétrica e pontuda em torno do zero, longe de um sino. O alvo é o plano $x$–$y$; quando você empilha a frequência dos erros dos dois eixos como altura, sobre esse plano, o que emerge é o sino da Normal.
A Figura 2 mostra esse processo em ação. Antes de mais nada, vale entender o que cada coluna representa: a 1ª coluna (X / Y) é onde os dardos caem no alvo; as 2ª e 3ª colunas (densidade em X e em Y) são a frequência desses erros projetada em cada eixo; e a 4ª coluna (3D) é a superfície que aparece quando você empilha essas duas projeções como altura sobre o plano, exatamente o "empilhar como altura" descrito acima.
O detalhe que costura tudo está nas linhas. Cada ponto não é um arremesso solto: é a posição média do lançador ao longo de $k$ rodadas (de "1 round" a "1000 rounds"). É aqui que a metáfora encontra o $n \to \infty$ da versão formal: aumentar o número de rodadas é aumentar o $n$ da média amostral. Repare no que acontece descendo as linhas: a densidade por eixo, que começa pontuda e enviesada (herança da Exponencial), vai cedendo e se arredondando até virar o sino simétrico da Normal. A origem é "anti-sino", mas a média, à medida que acumulamos rodadas, não tem para onde fugir.
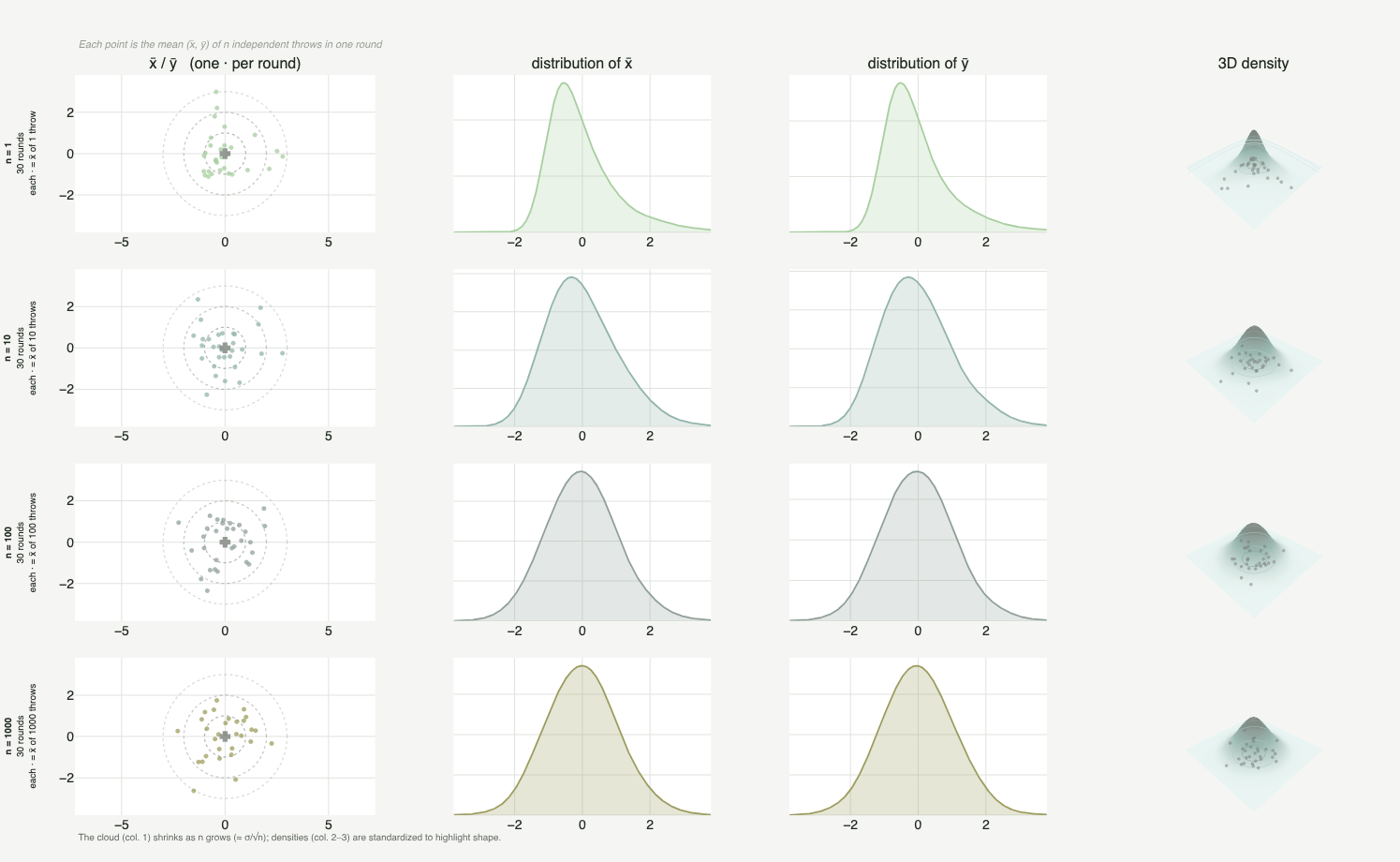
A média sobrevive; o desvio padrão se transforma
Espero que esse convencimento tenha sido suficiente (ou ao menos plausível). Dele tiramos que a média da distribuição original é "preservada" na nova Normal. Já o desvio padrão não tem uma tradução tão direta: o desvio padrão da Normal resultante é $\sigma/\sqrt{n}$, e não o $\sigma$ original. Foi exatamente isso que vimos a nuvem de dardos fazer na Figura 2, encolhendo a cada linha conforme as rodadas aumentavam.
A intuição é até simples. Quando você soma a média de $n$ variáveis, a média final é a soma das médias dividida por $n$. Com a variância (e o desvio padrão) o jogo é outro: a soma desses valores cresce com $n$, e dividir por $\sqrt{n}$ é a forma de regularizar essa métrica diante das $n$ variáveis. Não é exatamente isso, mas é a intuição que sustenta o argumento.
E de onde vem esse $\pi$?
Mesmo depois de tudo isso, sobra um incômodo: "Já vi inúmeras curvas normais na vida, de onde sai esse $\pi$? O que a Normal tem a ver com um círculo?"
De fato não parece natural que uma distribuição que aparece o tempo todo na natureza traga um círculo embutido na definição. E por que, de todas as distribuições, é justo a Normal (gaussiana, para os íntimos) que se repete tanto assim? Deixando de lado teorias da conspiração e numerologia, a gaussiana tem algumas propriedades intrigantes que ajudam a justificar a fama.
O famoso argumento de Herschel–Maxwell dá a intuição. Suponha que você procura uma distribuição com simetria radial num plano ($x$ e $y$) e que possa ser decomposta em dois fatores, um para cada eixo. A única solução que emerge é a gaussiana (aqui entra o nosso primeiro axioma da fé: para evitar contas pesadas, você vai ter de acreditar que essa afirmação é verdadeira). É a mesma simetria radial que você viu surgir na 4ª coluna da Figura 2: o sino que aparece sobre o plano $x$–$y$ tem o mesmo aspecto visto de qualquer direção.
Por causa dessa simetria radial, surge uma área circular: se você decompõe o valor total $r$ radialmente em $x$ e $y$, recai na fórmula do raio do círculo, $r^2 = x^2 + y^2$. É dessa relação que o $\pi$ aparece (é também aqui que entra o famoso truque da integral de $e^{-x^2}$ via coordenadas polares, popularmente associado a Poisson). E como as manipulações em 2D que resolvem a distribuição usam essa simetria radial, quando você projeta a solução de volta para 1D o $\pi$ permanece, só que agora sob uma raiz, que é exatamente o $\sqrt{2\pi}$ que mora no denominador da PDF.
Gaussiana + Gaussiana = Gaussiana
Uma consequência dessa mesma ideia (interessante pelo menos para quem chegou até aqui, os que abandonaram o texto provavelmente não acharão tão divertido): a soma de duas variáveis aleatórias gaussianas independentes é uma nova variável gaussiana.
Parece óbvio, mas tem uma sutileza. Somar duas variáveis de uma mesma distribuição em geral não preserva a distribuição, embora várias famílias também tenham essa propriedade (Poisson, Gama com mesma escala e até a Cauchy são fechadas sob soma). O que torna a gaussiana especial é outra coisa: ela é a única distribuição estável com variância finita, e é o mesmo fator de decomposição radial que garante isso.
Daí dá para arriscar uma generalização. Se você soma "infinitas" variáveis (de variância finita) e acredita que o resultado deve ser alguma distribuição estável, a única candidata capaz de se manter intacta ao longo do processo é a gaussiana (de novo, axioma da fé). E aqui reencontramos o TLC por outro caminho: partindo de qualquer distribuição de variância finita, ao somar infinitas variáveis de mesma distribuição você se aproxima de alguma distribuição-limite, e a única que não se degrada nesse processo é a Normal. Você "deforma" a distribuição até ela chegar na Normal e, dali em diante, ela permanece intacta. (Sem variância finita o destino muda: somas de variáveis de cauda pesada, como a Cauchy, convergem para outras leis estáveis, é o TLC generalizado.)
Até onde dá para afrouxar as hipóteses
A última curiosidade é justamente saber quão longe podemos relaxar as hipóteses iniciais. Dá para abrir mão da independência (martingales) e até estender o teorema para a alta dimensão: o teorema do limite central para corpos convexos, de Klartag, mostra que as projeções (marginais) de distribuições log-côncavas em dimensão alta, como a uniforme sobre um corpo convexo, são aproximadamente gaussianas. Não são todos os caminhos, mas são muitos os que levam à Normal.
Se você quer conhecer mais sobre esse teorema poderoso e o quão longe já chegamos nesse ramo da matemática, vale percorrer as referências abaixo. Há provas, recursos com estas e outras intuições, e um bom ponto de partida para entender, em nível universitário, essa "mágica" da estatística.
Referências
- Sanderson, G. (3Blue1Brown) (2023). But what is the Central Limit Theorem? [vídeo]. YouTube.
- Sanderson, G. (3Blue1Brown) (2023). Why π is in the normal distribution (beyond integral tricks) [vídeo]. YouTube.
- Sanderson, G. (3Blue1Brown) (2023). Convolutions | Why X+Y in probability is a beautiful mess [vídeo]. YouTube.
- Sanderson, G. (3Blue1Brown) (2023). A pretty reason why Gaussian + Gaussian = Gaussian [vídeo]. YouTube.
- Lindeberg, J. W. (1922). Eine neue Herleitung des Exponentialgesetzes in der Wahrscheinlichkeitsrechnung. Mathematische Zeitschrift, 15(1), 211–225.
- Feller, W. (1935). Über den zentralen Grenzwertsatz der Wahrscheinlichkeitsrechnung. Mathematische Zeitschrift, 40(1), 521–559.
- Esseen, C.-G. (1942). On the Liapunov limit of error in the theory of probability. Arkiv för Matematik, Astronomi och Fysik, A28, 1–19.
- Shevtsova, I. (2011). On the absolute constants in the Berry-Esseen type inequalities for identically distributed summands. arXiv preprint.
- Stein, C. (1972). A bound for the error in the normal approximation to the distribution of a sum of dependent random variables. Proceedings of the Sixth Berkeley Symposium on Mathematical Statistics and Probability, 2, 583–602.
- Chen, L. H. Y., Goldstein, L., & Shao, Q. M. (2011). Normal Approximation by Stein's Method. Springer.
- Billingsley, P. (1995). Probability and Measure (3rd ed.). Wiley.
- Bradley, R. C. (2007). Introduction to Strong Mixing Conditions. Kendrick Press.
- Klartag, B. (2007). A central limit theorem for convex sets. Inventiones Mathematicae, 168(1), 91–131.
- Fischer, H. (2011). A History of the Central Limit Theorem: From Classical to Modern Probability Theory. Springer.
- Le Cam, L. (1986). The Central Limit Theorem around 1935. Statistical Science, 1(1), 78–91.
- Durrett, R. (2019). Probability: Theory and Examples (5th ed.). Cambridge University Press.
- van der Vaart, A. W. (1998). Asymptotic Statistics. Cambridge University Press.
- Tao, T. (2010). 254A, Notes 2: The central limit theorem. What's New (blog).
- Tao, T. (2015). 275A, Notes 4: The central limit theorem. What's New (blog).
- Tao, T. (2015). 275A, Notes 5: Variants of the central limit theorem. What's New (blog).
- Chin, C. W. (2021). A Short and Elementary Proof of the Central Limit Theorem by Individual Swapping. arXiv preprint, arXiv:2106.00871.
- Wikipedia contributors. Central limit theorem. Wikipedia, The Free Encyclopedia.